Accelerazione GPU in COMSOL Multiphysics®
Le ultime versioni di COMSOL Multiphysics® introducono nuove funzionalità per accelerare le simulazioni utilizzando le unità di elaborazione grafica (GPU) NVIDIA®. Questi miglioramenti ampliano la gamma di modelli che possono trarre vantaggio dall'hardware GPU; includono risolutori sparsi diretti applicabili a qualsiasi applicazione fisica singola o multifisica, nonché il supporto per simulazioni acustiche di pressione esplicite nel tempo e l'addestramento di modelli surrogati con reti neurali profonde (DNN). Nella versione 6.4, il supporto GPU per i solutori diretti è completamente integrato nel framework del solutore standard, consentendo agli utenti di sfruttare l'accelerazione GPU per i modelli esistenti senza dover apportare modifiche alle impostazioni fisiche sottostanti.
Accelerazione GPU per risolutori sparsi diretti
Una delle fasi più dispendiose in termini di tempo in molte simulazioni agli elementi finiti è la risoluzione ripetuta di grandi sistemi lineari sparsi. Tali sistemi derivano da passi temporali impliciti, iterazioni non lineari, analisi delle frequenze proprie e scansioni dei parametri. Per affrontare questo tipo di studi, la versione 6.4 di COMSOL Multiphysics® include ora il solutore diretto sparso NVIDIA CUDA® (cuDSS). Questo solutore esegue fattorizzazioni di matrici con una o più GPU su un singolo computer, sfruttando l'elevata larghezza di banda della memoria e il massiccio parallelismo forniti dai recenti hardware GPU.
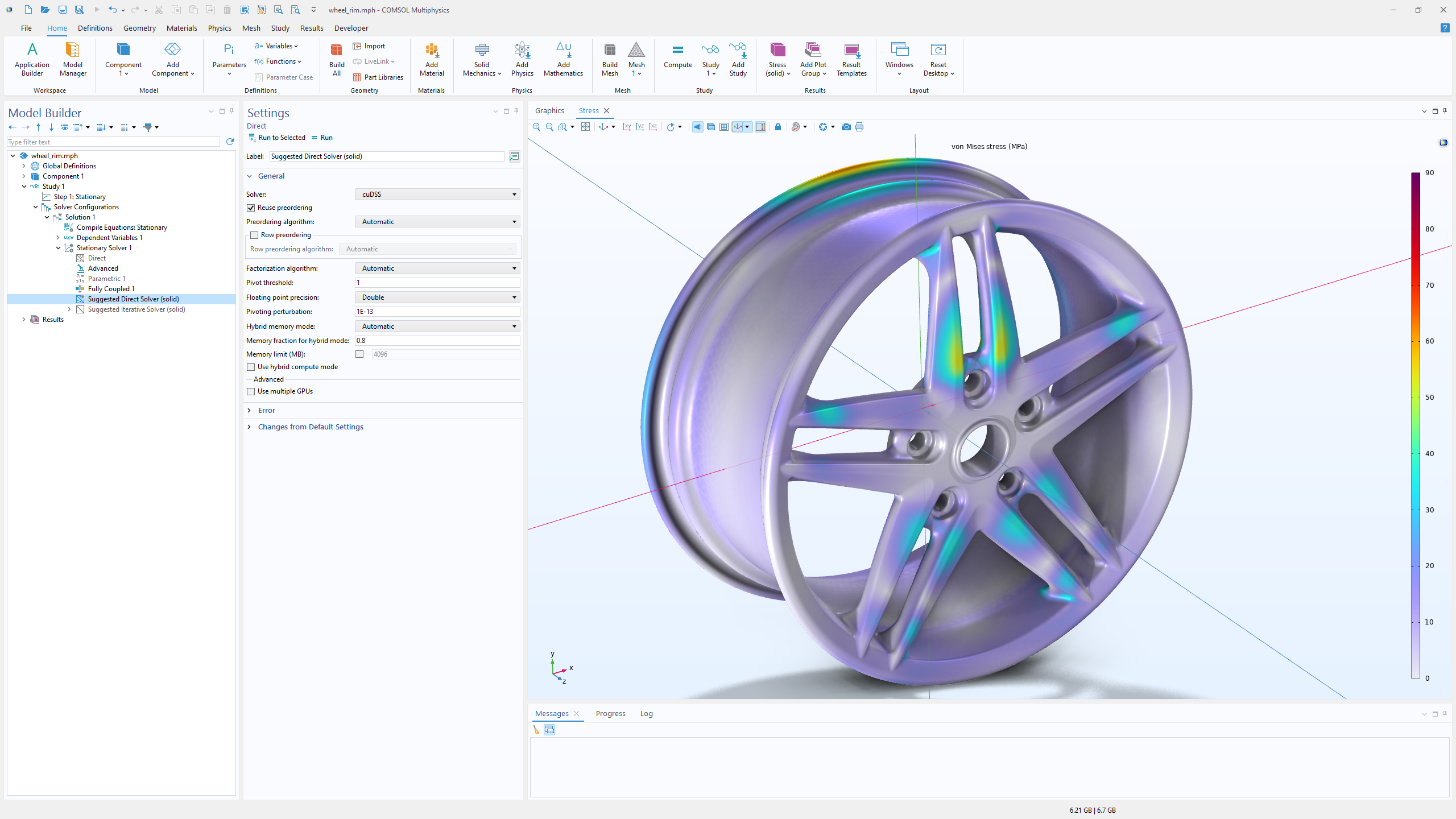
I miglioramenti delle prestazioni variano a seconda delle applicazioni, ma sono state osservate riduzioni significative dei tempi di esecuzione per modelli con diversi milioni di gradi di libertà (DOF). Ad esempio, per una simulazione di benchmark acustico termoviscoso che coinvolge un'analisi multifisica della trasmissione acustica attraverso una piastra perforata, la risoluzione su più GPU NVIDIA® H100 ha portato a tempi di esecuzione notevolmente più brevi rispetto a un sistema CPU a doppio processore. Anche i modelli standard di meccanica strutturale mostrano chiari miglioramenti quando si scarica la fase di risoluzione diretta su GPU di classe workstation come la RTX 5000 Ada.
L'implementazione cuDSS supporta sia l'aritmetica a doppia precisione che quella a precisione singola. Poiché la precisione singola riduce dell'50% l'utilizzo della memoria, può aumentare le prestazioni su qualsiasi scheda in cui l'applicazione è limitata dalla memoria, comprese le GPU a basso costo. L'idoneità di un particolare modello alla precisione singola dipende dal suo condizionamento numerico, che è influenzato dalla qualità della mesh, dai parametri dei materiali e dalla fisica sottostante. Gli utenti possono testare le modalità di precisione direttamente nelle impostazioni del solutore e selezionare la modalità che fornisce sia risultati stabili che le prestazioni desiderate.
Acustica di pressione esplicita nel tempo accelerata da GPU
Il supporto GPU NVIDIA® è disponibile anche per la simulazione acustica di pressione esplicita nel tempo. Quando si esegue questo tipo di simulazione, è possibile evitare di risolvere grandi sistemi lineari a ogni passo temporale utilizzando metodi espliciti di passo temporale che si basano invece su operazioni vettoriali ripetute e aggiornamenti di elementi locali. Queste operazioni sono altamente parallelizzabili e si mappano in modo efficiente sull'hardware GPU.
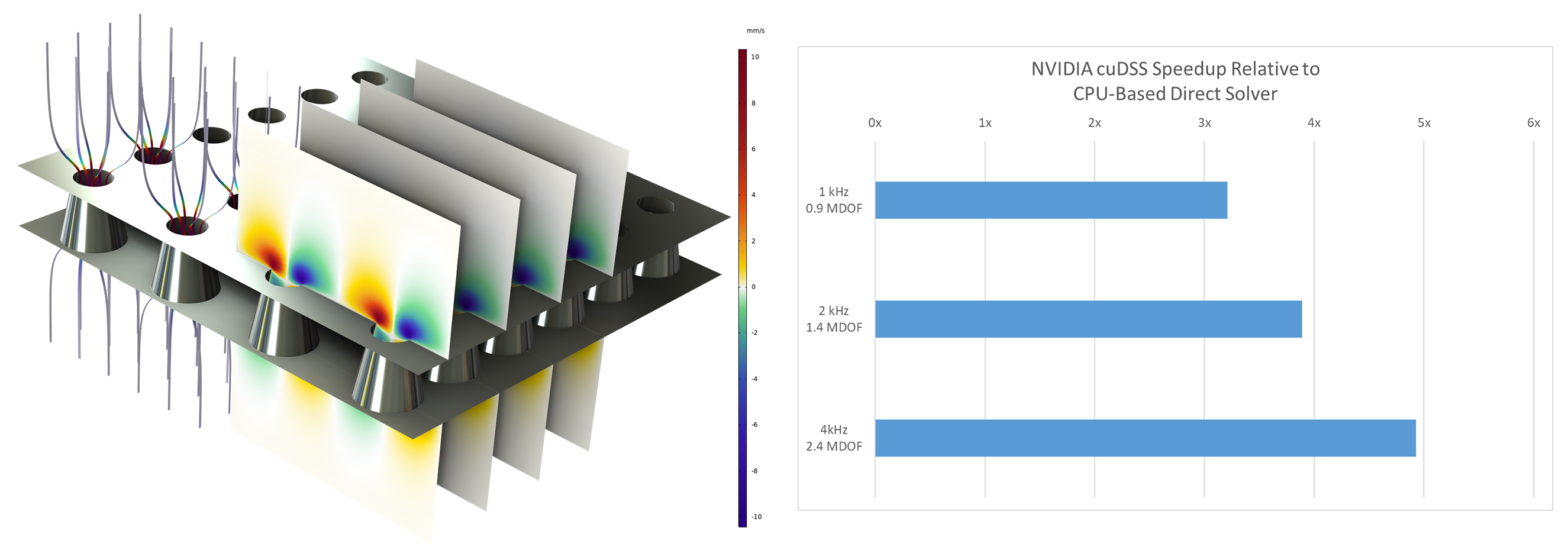
Questa capacità è particolarmente rilevante per le simulazioni acustiche a banda larga e i domini 3D di grandi dimensioni, dove una risoluzione spaziale fine porta a un numero elevato di passi temporali. Ad esempio, i modelli acustici di ambienti come uffici o sale da concerto possono richiedere decine di migliaia di passi temporali per risolvere con precisione la propagazione delle onde. Scaricare queste operazioni sulle GPU può ridurre notevolmente il tempo complessivo di simulazione.
La formulazione accelerata da GPU per l'acustica esplicita supporta sia sistemi a GPU singola che multi-GPU, su un singolo computer così come su nodi cluster. Ciò rende possibile simulare domini con centinaia di milioni di DOF. Ad esempio, in un modello basato sulle onde di una sala da concerto, una simulazione che coinvolgeva circa 300 milioni di DOF è stata completata in poche ore su una singola GPU NVIDIA® H100 di livello data center, rispetto alle diverse ore necessarie su più nodi CPU. Riduzioni simili dei tempi di esecuzione si possono osservare negli esempi di acustica automotive e in altre analisi transitorie su larga scala.
Nota: l'interfaccia Pressure Acoustics, Time Explicit è supportata per tutti i tipi di licenza quando si utilizza una singola GPU, ma richiede una licenza di rete flottante quando si utilizzano più GPU.
Propagazione di un impulso iniziale (centrato a 500 Hz) in un modello di sala da concerto con 300 milioni di gradi di libertà, risolto su una GPU NVIDIA® H100 di livello data center.
Supporto GPU per l'addestramento di modelli surrogati
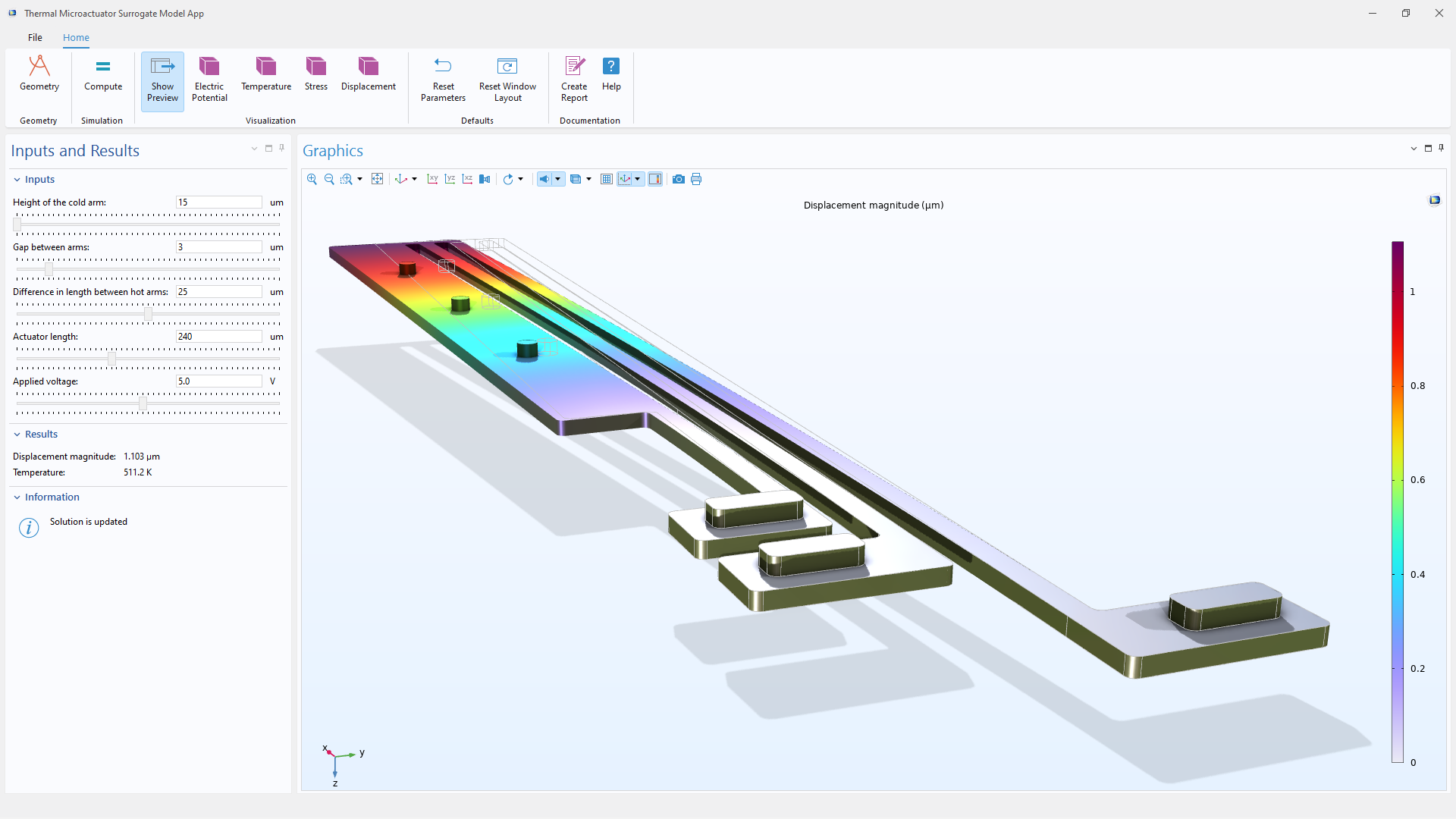
COMSOL Multiphysics® fornisce anche strumenti per la generazione di modelli surrogati DNN che approssimano simulazioni numeriche ad alta precisione. L'addestramento di queste reti richiede una valutazione ripetuta di grandi set di dati e molti cicli di ottimizzazione, che ben si adattano all'accelerazione GPU. Eseguendo il processo di addestramento su una GPU NVIDIA®, gli utenti possono ridurre il tempo necessario per esplorare le architetture di rete o regolare gli iperparametri.
Anche le reti più grandi, che possono essere necessarie per catturare comportamenti multifisici complessi o ricostruire modelli spaziali, traggono vantaggio dalla maggiore larghezza di banda di memoria e dalla capacità di calcolo parallelo delle GPU. Il supporto GPU per l'addestramento DNN è abilitato direttamente nell'interfaccia Surrogate Model e funziona senza prodotti aggiuntivi.
Ulteriori approfondimenti
Per ulteriori informazioni sull'accelerazione GPU in COMSOL Multiphysics®, consultare:
- COMSOL Multiphysics® 6.4 Novità principali della versione: aggiornamenti relativi agli studi e ai solutori
- COMSOL Multiphysics® 6.4 Novità principali della versione: Aggiornamenti dell'Acoustics Module
- Requisiti di sistema: COMSOL Multiphysics® versione 6.4
- Configurazione del calcolo accelerato da GPU in COMSOL Multiphysics®
NVIDIA, CUDA e RTX sono marchi commerciali e/o marchi registrati di NVIDIA Corporation negli Stati Uniti e/o in altri paesi. Intel e Xeon sono marchi commerciali di Intel Corporation negli Stati Uniti e/o in altri paesi.